Installare Ollama e il modello llama3 8b
Ollama è una piattaforma per eseguire large language models (LLMs) sul proprio computer o server in locale. Una volta installato Ollama è necessario scaricare anche un modello per poter utilizzare un prompt che ci consentirà di interrogare l’intelligenza artificiale.
Ci sono un grande numero di modelli disponibili sulla piattaforma di Ollama che sono anche gratuiti.
Fra i modelli gratuiti (e open source) abbiamo: Llama 3/3.1, Mistral, Gemma 2/3, Phi-3, CodeLlama, e Mixtral, questi sono stati rilasciati con licenze aperte come la Llama Community License oppure Apache License 2.0. Anche la versione DeepSeek-V3 (che non s’appoggia sul cloud per funzionare) è gratuita.
Tuttavia non è sempre possibile utilizzare qualsiasi modello sul nostro PC, infatti alcuni modelli possono essere molto pesanti da utilizzare e richiedono molta memoria e molta capacità di elaborazione. Modelli come Llama 3 70B richiedono un minimo di 64 GB di RAM per essere utilizzati con un discreto tempo di risposta, ma esistono anche modelli molto semplificati che richiedono solo meno di 1 GB per funzionare molto fluidamente come Gemma 270M il cui file del modello occupa circa 300 MB e può girare interamente nella RAM di uno smartphone.
Uno dei modelli più apprezzati che funzionano bene con non troppa RAM (12-16 GB), una cpu con 4 core senza utilizzare una GPU è Llama3 8B. Esso nel formato quantizzato, usato da Ollama, richiede circa 5 GB di memoria per caricare i suoi parametri, quindi è possibile utilizzarlo anche con 8 GB di RAM ma è consigliato salire ad almeno 12 GB per avere un funzionamento più fluido.
Installare Ollama su Linux
Vediamo come installare Ollama su Linux, nel mio caso utilizzerò Debian 13 ma i passaggi sono simili anche per altre distribuzioni.
La prima cosa da fare è installare il pacchetto curl se non già fatto:
apt install curl
Installato curl possiamo procedere al download e all’installazione di ollama in un solo comando:
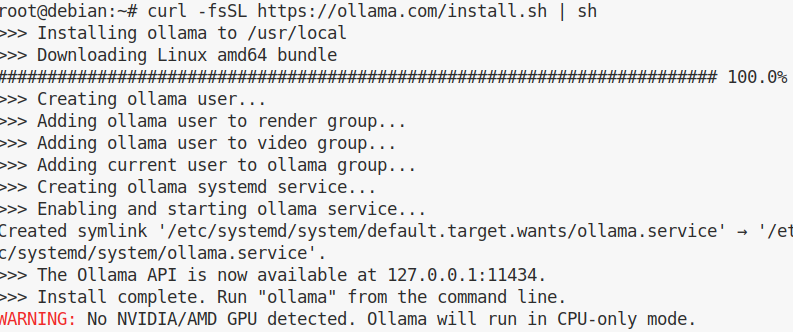
curl -fsSL https://ollama.com/install.sh | sh

In base alla velocità della nostra connessione, il pacchetto di ollama verrà scaricato e installato come potete vedere:
Se per qualche motivo la connessione dovesse cadere dovrete ricominciare il dowload:
Come si può vedere dall’output non è stata riconoscita una scheda video NVIDIA/AMD e verrà usata solo la CPU per l’elaborazione delle richieste:
Utilizziamo il modello Llama 3
Terminato il download di Ollama è possibile scaricare il modello Llama3 8b tramite il comando ollama pull llama3:8b
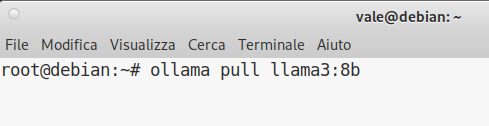
Vengono scaricati circa 4,7 GB di dati.
Al termine dello scaricamento è possibile lanciare il modello.
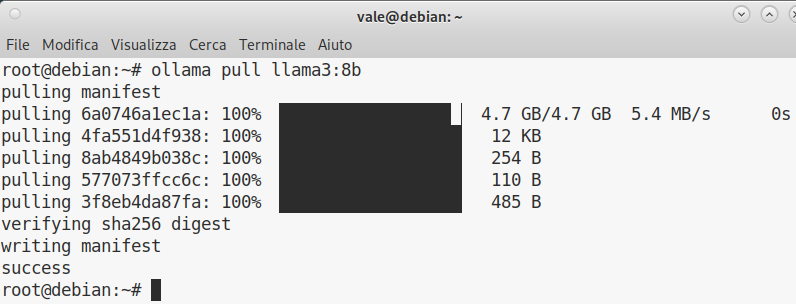
Il modello Llama3 8b è avviabile con il comando ollama run llama3:8b
Teniamo presente che più è grande il modello e più tempo richiede l’avvio del programma.
Come prima domanda, poniamo la semplice questione: “parli italiano?” che va scritta nel prompt e poi premiamo invio ed ecco la risposta:
Come ribadito precedentemente, la velocità di risposta dipende dalle risorse del nostro PC, con risorse adeguate il modello è in grado di stampare a video parecchie parole al secondo. Per uscire dal modello è sufficiente digitare una riga con scritto /bye